Coopetition-Gym Documentation
Multi-Agent Reinforcement Learning Environments for Strategic Coopetition
![]()
![]()
![]()
![]()
Compatibility and Requirements
Framework Compatibility
| Framework | Version | Status | Notes |
|---|---|---|---|
| Python | 3.9, 3.10, 3.11 | Tested | 3.9+ required |
| Gymnasium | 0.29+ | Compatible | Farama Foundation standard |
| PettingZoo | 1.24+ | Compatible | Parallel and AEC APIs |
| NumPy | 1.21+ | Required | Core dependency |
| SciPy | 1.7+ | Required | Mathematical functions |
MARL Framework Integration
| Framework | Integration | Notes |
|---|---|---|
| Stable-Baselines3 | Direct | Use Gymnasium API with VecEnv |
| RLlib | Direct | Use PettingZoo API with MultiAgentEnv |
| TorchRL | Compatible | Use Gymnasium API |
| CleanRL | Compatible | Single-file implementations |
Verification
import coopetition_gym
import gymnasium
import pettingzoo
# Verify installation
print(f"Coopetition-Gym environments: {len(coopetition_gym.list_environments())}")
print(f"Gymnasium version: {gymnasium.__version__}")
print(f"PettingZoo version: {pettingzoo.__version__}")
# Quick environment test
env = coopetition_gym.make("TrustDilemma-v0")
obs, info = env.reset(seed=42)
print(f"Observation shape: {obs.shape}")
print(f"Action space: {env.action_space}")
Overview
Coopetition-Gym is a Python research library providing multi-agent reinforcement learning environments for studying coopetitive dynamics,scenarios where agents must simultaneously cooperate and compete. The library implements mathematical frameworks from published research:
- TR-1: Computational Foundations for Strategic Coopetition: Formalizing Interdependence and Complementarity
- TR-2: Computational Foundations for Strategic Coopetition: Formalizing Trust and Reputation Dynamics
- TR-3: Computational Foundations for Strategic Coopetition: Formalizing Collective Action and Loyalty
- TR-4: Computational Foundations for Strategic Coopetition: Formalizing Sequential Interaction and Reciprocity
Key Features
- 20 Specialized Environments spanning dyadic relationships to multi-agent ecosystems
- Validated Case Studies based on real business partnerships (Samsung-Sony, Renault-Nissan, Apache, Apple App Store)
- Trust Dynamics with asymmetric updating and reputation hysteresis
- Multiple APIs: Gymnasium (single-agent), PettingZoo Parallel, and PettingZoo AEC
- Configurable Parameters for research flexibility
Modeling Approach
Coopetition-Gym v1.x implements the uniaxial treatment of coopetition, modeling strategic choice along the cooperation-defection continuum (Bengtsson & Kock, 2000). Agents choose cooperation levels in [0, endowment], with competitive dynamics emerging through structural parameters (interdependence matrix, bargaining shares, trust evolution). This foundational approach enables computational tractability while capturing core coopetitive phenomena validated against real-world cases.
Future versions will introduce biaxial treatment with independent cooperation and competition dimensions, following Brandenburger & Nalebuff (1996). See Scope and Strategic Roadmap for theoretical rationale and extension plans.
Quick Start
Installation
# Clone the repository
git clone https://github.com/your-org/strategic-coopetition.git
cd strategic-coopetition/coopetition_gym
# Install in development mode
pip install -e .
# Install with all dependencies
pip install -e ".[dev,viz,rl]"
Basic Usage
import coopetition_gym
import numpy as np
# Create environment
env = coopetition_gym.make("TrustDilemma-v0")
# Reset and run episode
obs, info = env.reset(seed=42)
done = False
while not done:
# Agents choose cooperation levels
actions = np.array([50.0, 50.0]) # 50% cooperation each
obs, rewards, terminated, truncated, info = env.step(actions)
done = terminated or truncated
print(f"Final trust: {info['mean_trust']:.2f}")
PettingZoo APIs
# Parallel API (simultaneous moves)
env = coopetition_gym.make_parallel("PlatformEcosystem-v0")
observations, infos = env.reset()
actions = {agent: env.action_space(agent).sample() for agent in env.agents}
observations, rewards, terminations, truncations, infos = env.step(actions)
# AEC API (sequential moves)
env = coopetition_gym.make_aec("TrustDilemma-v0")
env.reset()
for agent in env.agent_iter(): obs, reward, term, trunc, info = env.last()
action = policy(obs) if not term else None
env.step(action)
Environment Categories
Coopetition-Gym provides 20 environments organized into 7 categories:
Dyadic Environments (2-Agent)
Micro-level scenarios modeling direct partnerships between two agents.
| Environment | Description | Key Challenge |
|---|---|---|
| TrustDilemma-v0 | Continuous Prisoner’s Dilemma with trust dynamics | Long-horizon impulse control |
| PartnerHoldUp-v0 | Asymmetric power relationship | Power dynamics and exploitation |
Ecosystem Environments (N-Agent)
Macro-level scenarios with multiple interacting agents.
| Environment | Description | Key Challenge |
|---|---|---|
| PlatformEcosystem-v0 | Platform with N developers | Ecosystem health management |
| DynamicPartnerSelection-v0 | Reputation-based partner matching | Social learning and signaling |
Benchmark Environments
Research-focused environments for algorithm evaluation.
| Environment | Description | Key Challenge |
|---|---|---|
| RecoveryRace-v0 | Post-crisis trust recovery | Planning under trust constraints |
| SynergySearch-v0 | Hidden complementarity discovery | Exploration vs. exploitation |
Validated Case Studies
Environments with parameters validated against real business data.
| Environment | Description | Validation |
|---|---|---|
| SLCD-v0 | Samsung-Sony S-LCD Joint Venture | 58/60 accuracy |
| RenaultNissan-v0 | Renault-Nissan Alliance phases | Multi-phase dynamics |
Extended Environments
Advanced scenarios with additional mechanics.
| Environment | Description | Key Mechanics |
|---|---|---|
| CooperativeNegotiation-v0 | Multi-round negotiation | Commitment and breach penalties |
| ReputationMarket-v0 | Market with reputation tiers | Reputation as strategic asset |
Collective Action Environments (TR-3)
Team production and collective action scenarios with loyalty dynamics.
| Environment | Description | Key Challenge |
|---|---|---|
| TeamProduction-v0 | Team production with free-rider dynamics | Nash equilibrium baseline |
| LoyaltyTeam-v0 | Team production with loyalty mechanisms | Sustaining above-Nash cooperation |
| CoalitionFormation-v0 | Dynamic coalition with entry/exit | Coalition stability under exclusion |
| ApacheProject-v0 | Apache HTTP Server case study (52/60) | Phase-dependent contributor dynamics |
| PublicGoods-v0 | Classic public goods game | Contribution and punishment dynamics |
Reciprocity Environments (TR-4)
Sequential interaction and reciprocity scenarios with bounded memory.
| Environment | Description | Key Challenge |
|---|---|---|
| ReciprocalDilemma-v0 | Continuous PD with direct reciprocity | Conditional cooperation via memory |
| GiftExchange-v0 | Asymmetric employer-worker exchange | Asymmetric reciprocity sensitivity |
| IndirectReciprocity-v0 | 4-agent reputation-mediated cooperation | Indirect reciprocity via image scoring |
| GraduatedSanction-v0 | 6-agent commons with graduated sanctions | Proportional punishment and escalation |
| AppleAppStore-v0 | Apple iOS App Store (validated 48/55) | Platform power and reciprocity dynamics |
Core Concepts
For Researchers: Full mathematical derivations, proofs, and validation methodology are available in the Theoretical Foundations documentation and the published technical reports.
For Practitioners: The summaries below provide the essential intuition needed to use the environments effectively.
Coopetitive Dynamics
Coopetition occurs when entities simultaneously cooperate (to create value) and compete (to capture value). As Brandenburger and Nalebuff articulated: actors “cooperate to grow the pie and compete to split it up.”
Real-World Examples:
- Technology Standards: Competitors collaborate on standards while competing in products (e.g., Bluetooth SIG members)
- Joint Ventures: Partners invest jointly but negotiate surplus division (e.g., Samsung-Sony S-LCD)
- Platform Ecosystems: Developers depend on platforms that also compete with them (e.g., iOS App Store)
- Supply Chains: Suppliers share information for efficiency while competing for contracts
The Coopetition Paradox: The same relationship exhibits both cooperative and competitive dynamics simultaneously, not sequentially or in separate domains. This creates strategic tension that standard game theory struggles to capture.
Interdependence & Structural Coupling (TR-1)
Interdependence captures why actors must consider partner outcomes even while competing. When Actor A depends on Actor B for critical resources, A’s success structurally requires B’s success, creating instrumental concern for B’s welfare distinct from altruism.
The Interdependence Matrix quantifies structural dependencies:
\[\Large D_{ij} = \frac{\sum_{d \in \mathcal{D}_i} w_d \cdot \text{Dep}(i,j,d) \cdot \text{crit}(i,j,d)}{\sum_{d \in \mathcal{D}_i} w_d}\]| Component | Meaning | Example |
|---|---|---|
| $w_d$ | Importance weight of goal d | Revenue goal: 0.8, Brand goal: 0.2 |
| $\text{Dep}(i,j,d)$ | Does i depend on j for d? | Developer depends on platform for distribution |
| $\text{crit}(i,j,d)$ | Criticality (1 = sole provider) | API provider with no alternatives: 1.0 |
Key Insight: $D_{ij} \neq D_{ji}$ in general. Asymmetric dependencies create power imbalances, a startup may critically depend on a platform ($D_{\text{startup,platform}} \approx 0.8$) while the platform barely notices any single startup ($D_{\text{platform,startup}} \approx 0.01$).
Integrated Utility Function (TR-1)
Agents maximize integrated utility that accounts for partner outcomes through structural coupling:
\[\Large U_i(\mathbf{a}) = \pi_i(\mathbf{a}) + \sum_{j \neq i} D_{ij} \cdot \pi_j(\mathbf{a})\]Components Explained:
| Term | Formula | Intuition |
|---|---|---|
| Private Payoff | $\pi_i = e_i - a_i + f(a_i) + \alpha_i \cdot \text{Synergy}$ | What I keep + what I create + my share of joint value |
| Interdependence Term | $\sum_{j} D_{ij} \cdot \pi_j$ | Partner success weighted by my dependency on them |
Why This Matters: Classical Nash Equilibrium assumes purely self-interested payoffs. The Coopetitive Equilibrium extends Nash by incorporating dependency-weighted concern for partner outcomes, capturing why dependent actors rationally care about partner success.
Value Creation & Complementarity (TR-1)
Complementarity creates the cooperative incentive: joint action produces superadditive value exceeding independent contributions.
\[\Large V(\mathbf{a} \mid \gamma) = \sum_{i=1}^{N} f_i(a_i) + \gamma \cdot g(a_1, \ldots, a_N)\]Two Validated Specifications:
| Specification | Individual Value $f(a)$ | Synergy $g(a)$ | Best For |
|---|---|---|---|
| Logarithmic (default) | $\theta \cdot \ln(1 + a_i)$, $\theta=20$ | Geometric mean | Manufacturing JVs (58/60 validation) |
| Power | $a_i^{\beta}$, $\beta=0.75$ | Geometric mean | General scenarios (46/60 validation) |
Key Parameters (validated across 22,000+ trials):
- $\theta = 20.0$: Logarithmic scale producing realistic cooperation magnitudes
- $\beta = 0.75$: Diminishing returns reflecting investment economics
- $\gamma = 0.65$: Complementarity strength balancing individual and joint value
Trust Dynamics (TR-2)
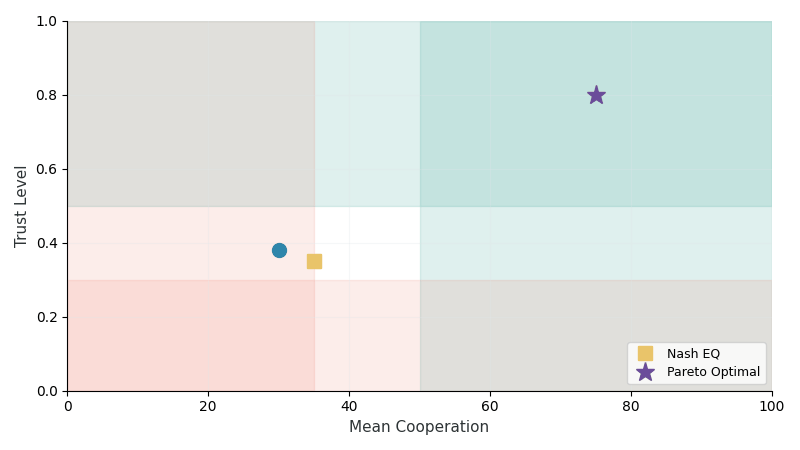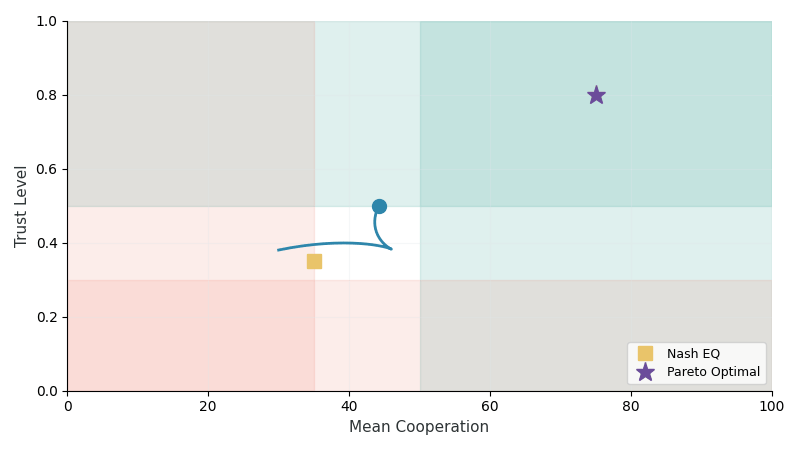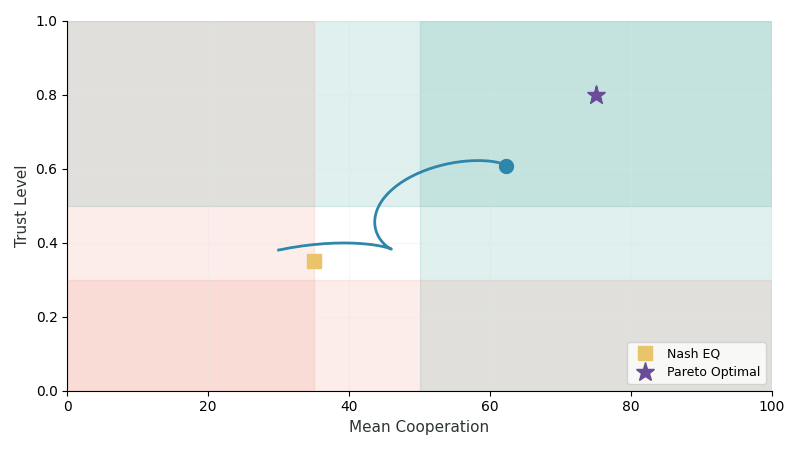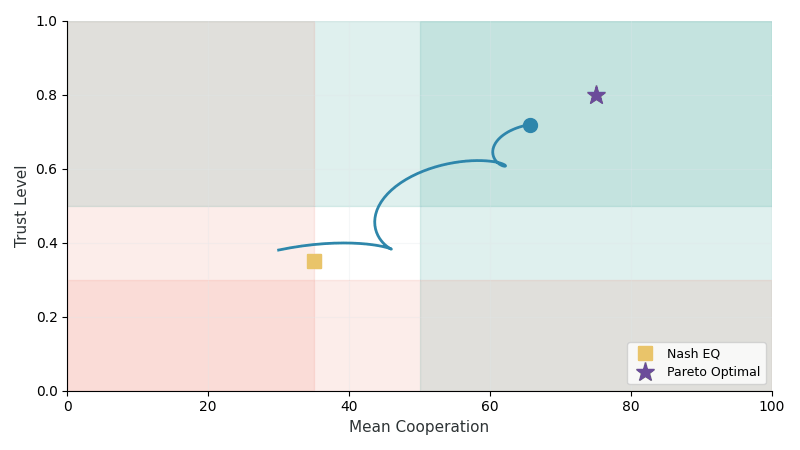
Trust evolves through a two-layer architecture capturing both immediate behavioral responses and long-term memory:
| Layer | Symbol | Updates | Captures |
|---|---|---|---|
| Immediate Trust | $T_{ij} \in [0,1]$ | Every interaction | Current confidence in partner |
| Reputation Damage | $R_{ij} \in [0,1]$ | On violations | Historical memory of betrayals |
Asymmetric Evolution with Negativity Bias:
\[\Delta T = \begin{cases} \lambda^+ \cdot s \cdot (\Theta - T) & \text{if } s > 0 \; [\lambda^+ = 0.10] \\ -\lambda^- \cdot |s| \cdot T \cdot (1 + \xi D) & \text{if } s \leq 0 \; [\lambda^- = 0.30] \end{cases}\]The 3:1 Ratio: Trust erodes approximately 3× faster than it builds ($\lambda^-/\lambda^+ \approx 3.0$). This negativity bias, validated against behavioral economics research, explains why:
- A single major violation can destroy months of trust-building
- Consistent cooperation is essential for sustainable partnerships
- Recovery from betrayal requires sustained effort over extended periods
Trust Ceiling Mechanism:
\[\Large \Theta = 1 - R \quad \text{(reputation damage limits maximum achievable trust)}\]Even with perfect cooperation, damaged reputation prevents trust from fully recovering, creating permanent relationship constraints (hysteresis).
Interdependence Amplification: High-dependency relationships experience 27% faster trust erosion for equivalent violations:
\[\Large \text{Erosion factor} = (1 + \xi \cdot D_{ij}) \quad \text{where } \xi = 0.50\]When you depend heavily on a partner, their betrayal hurts more.
Reciprocity Dynamics (TR-4)
Reciprocity captures how agents condition current behavior on observed partner actions over a bounded memory window. Unlike slow-moving trust (TR-2), reciprocity enables fast behavioral responses within 1-10 steps.
Cooperation Signal (Equation 19):
\[s_{ij} = a_j - \bar{a}_j \quad \text{(deviation from recent average)}\]Bounded Response (Equation 21):
\[\varphi(x) = \tanh(\kappa \cdot x) \quad \text{where } \kappa \text{ controls sensitivity}\]Reciprocity Modifier (Equation 44):
\[U_{\text{recip},i} = \lambda_R \sum_{j \neq i} T_{ij} \cdot (1 + \omega D_{ij}) \cdot \rho_{ij} \cdot \varphi(s_{ij})\]Key Property: Dependency-Scaled Reciprocity
\[\rho_{ij} = \rho_0 \cdot D_{ij}^{\eta} \quad \text{(higher dependency → stronger reciprocal response)}\]Agents who depend more on a partner reciprocate more strongly, capturing why workers respond to wage changes more than employers respond to effort changes.
Empirical Validation
The mathematical framework has been validated against real business partnerships, open source projects, and platform ecosystems:
| Case Study | Validation Score | Key Dynamics Captured |
|---|---|---|
| Samsung-Sony S-LCD (2004-2011) | 58/60 (96.7%) | Interdependence, complementarity, cooperation levels |
| Renault-Nissan Alliance (1999-2025) | 49/60 (81.7%) | Trust evolution, crisis, recovery across 5 phases |
| Apache HTTP Server (1995-2023) | 52/60 (86.7%) | Loyalty dynamics, phase transitions, contributor effort |
| Apple iOS App Store (2008-2024) | 48/55 (87.3%) | Reciprocity dynamics, platform power, phase transitions |
These validations ensure the environments produce realistic coopetitive dynamics rather than artificial constructs.
Learn More: See Theoretical Foundations for complete mathematical derivations, Parameter Reference for validated values, and Benchmark Results for algorithm performance analysis.
Observation and Action Spaces
Observation Space
All environments provide observations containing:
| Component | Shape | Description |
|---|---|---|
| Actions | (N,) |
All agents’ cooperation levels |
| Trust Matrix | (N, N) |
Pairwise trust levels |
| Reputation Matrix | (N, N) |
Pairwise reputation damage |
| Interdependence | (N, N) |
Structural dependencies |
| Step Count | (1,) |
Normalized timestep |
Action Space
Continuous actions representing cooperation level:
Box(low=0.0, high=endowment_i, shape=(1,), dtype=float32)
Higher actions = more cooperation/investment.
Common Parameters
Trust Parameters
| Parameter | Symbol | Typical Range | Description |
|---|---|---|---|
| Trust Building Rate | $\lambda^+$ | 0.08 - 0.15 | Speed of trust increase |
| Trust Erosion Rate | $\lambda^-$ | 0.25 - 0.45 | Speed of trust decrease |
| Reputation Damage | $\mu_R$ | 0.45 - 0.70 | Damage from violations |
| Reputation Decay | $\delta_R$ | 0.01 - 0.03 | Forgetting rate |
| Interdependence Amp. | $\xi$ | 0.40 - 0.70 | Dependency amplification |
| Signal Sensitivity | $\kappa$ | 1.0 - 1.5 | Action sensitivity |
Value Function Parameters
| Parameter | Symbol | Typical Range | Description |
|---|---|---|---|
| Logarithmic Scale | θ | 18 - 25 | Value magnitude |
| Complementarity | γ | 0.50 - 0.75 | Synergy from cooperation |
| Power Exponent | β | 0.70 - 0.80 | Diminishing returns |
Reciprocity Parameters (TR-4)
| Parameter | Symbol | Typical Range | Description |
|---|---|---|---|
| Base Reciprocity | $\rho_0$ | 0.6 - 1.2 | Reciprocity strength |
| Dependency Elasticity | $\eta$ | 1.0 - 1.5 | How dependency scales reciprocity |
| Response Sensitivity | $\kappa$ | 0.8 - 1.0 | Bounded response steepness |
| Memory Window | $k$ | 3 - 10 | Steps of recent history |
| Reciprocity Weight | $\lambda_R$ | 1.0 - 1.8 | Overall reciprocity scaling |
| Dependency Amplification | $\omega$ | 0.5 - 1.0 | Dependency boost in trust gating |
API Reference
Factory Functions
coopetition_gym.make(env_id, **kwargs)
# Returns: Gymnasium-compatible environment
coopetition_gym.make_parallel(env_id, **kwargs)
# Returns: PettingZoo ParallelEnv
coopetition_gym.make_aec(env_id, **kwargs)
# Returns: PettingZoo AECEnv
coopetition_gym.list_environments()
# Returns: List of available environment IDs
Common Methods
env.reset(seed=None, options=None)
# Returns: (observation, info)
env.step(action)
# Returns: (observation, reward, terminated, truncated, info)
env.render()
# Returns: Rendered output (if render_mode set)
env.close()
# Cleanup resources
Research Applications
Coopetition-Gym supports research in:
- Multi-Agent Reinforcement Learning: Test MARL algorithms on strategic interaction problems
- Game Theory: Study equilibria in repeated games with trust dynamics
- Mechanism Design: Evaluate incentive structures for cooperation
- Organizational Behavior: Model partnership dynamics and alliance management
- AI Safety: Understand cooperation emergence and breakdown
Citation
If you use Coopetition-Gym in your research, please cite:
@software{coopetition_gym,
title = {Coopetition-Gym: Multi-Agent RL Environments for Strategic Coopetition},
author = {Pant, Vik and Yu, Eric},
year = {2025},
institution = {Faculty of Information and Department of Computer Science, University of Toronto},
url = {https://github.com/your-org/strategic-coopetition}
}
@article{pant2025tr1,
title = {Computational Foundations for Strategic Coopetition: Formalizing Interdependence and Complementarity},
author = {Pant, Vik and Yu, Eric},
journal = {arXiv preprint arXiv:2510.18802},
year = {2025}
}
@article{pant2025tr2,
title = {Computational Foundations for Strategic Coopetition: Formalizing Trust and Reputation Dynamics},
author = {Pant, Vik and Yu, Eric},
journal = {arXiv preprint arXiv:2510.24909},
year = {2025}
}
@article{pant2026tr3,
title = {Computational Foundations for Strategic Coopetition: Formalizing Collective Action and Loyalty},
author = {Pant, Vik and Yu, Eric},
journal = {arXiv preprint arXiv:2601.16237},
year = {2026}
}
@article{pant2026tr4,
title = {Computational Foundations for Strategic Coopetition: Formalizing Sequential Interaction and Reciprocity},
author = {Pant, Vik and Yu, Eric},
journal = {arXiv preprint arXiv:2604.01240},
year = {2026}
}
License
Coopetition-Gym is released under the MIT License.
Navigation
Getting Started
Reference
- Environment Finder - Interactive tool to match research questions to environments
- Environment Reference
- API Documentation
- Parameter Reference
Theory & Research
- Theoretical Foundations
- Benchmark Results
- Implementation Roadmap
- Scope and Strategic Roadmap NEW - Modeling philosophy and future extensions
Development
Benchmark Highlights
We have evaluated 20 MARL algorithms across the 5 TR-1 environments and 5 TR-2 environments with 760 experiments totaling 76,000 evaluation episodes. Benchmarks for the 5 TR-3 collective action environments and 5 TR-4 reciprocity environments are forthcoming. Key findings:
| Finding | Implication |
|---|---|
| Simple heuristics (Constant_050) outperform all learning algorithms | Predictable cooperation builds trust |
| Trust-Return correlation: r = 0.552 | Trust causally drives performance |
| Population methods (Self-Play, FCP) fail catastrophically | Nash equilibria are Pareto-suboptimal |
| CTDE methods cluster together | Centralized critic dominates actor architecture |
See Benchmark Results for comprehensive analysis.