SynergySearch-v0
Category: Benchmark Environment
Agents: 2
Difficulty: Hard
Source: coopetition_gym/envs/benchmark_envs.py
Overview
SynergySearch-v0 presents an exploration vs. exploitation challenge where the complementarity parameter (γ) is hidden from agents. Agents must discover whether they have high or low synergy potential from reward signals alone, then adapt their strategy accordingly.
This environment tests agents’ ability to:
- Extract information from reward patterns
- Estimate hidden parameters through interaction
- Adapt strategy based on discovered synergy level
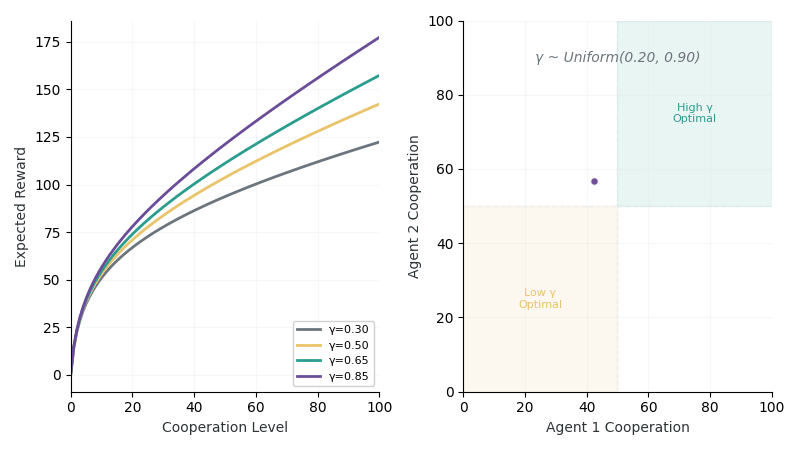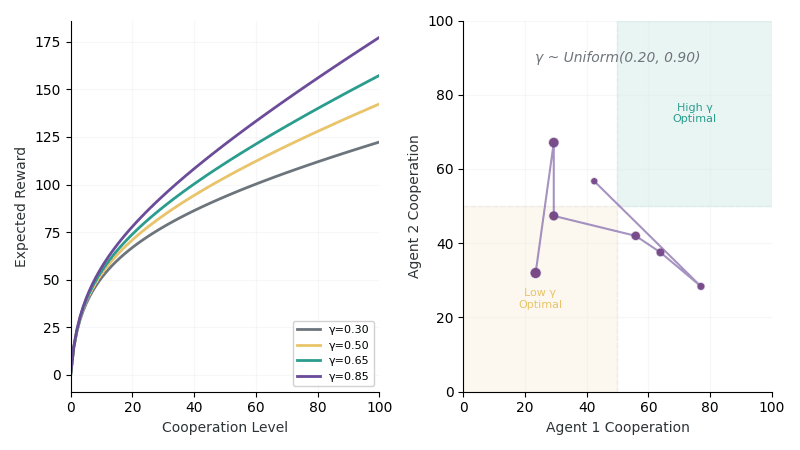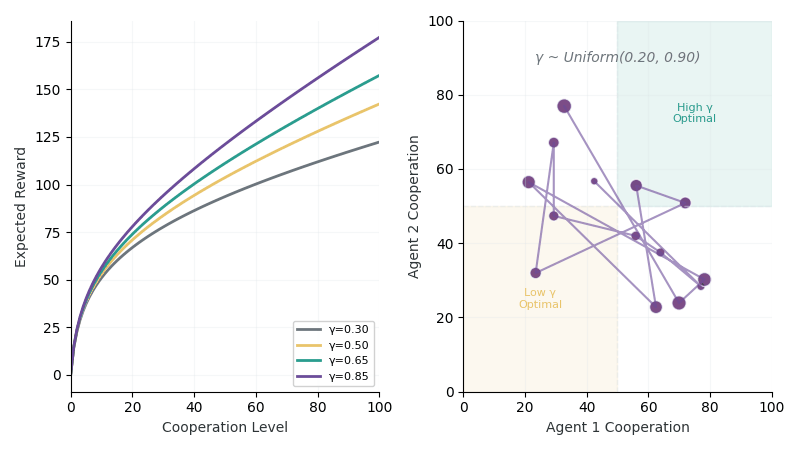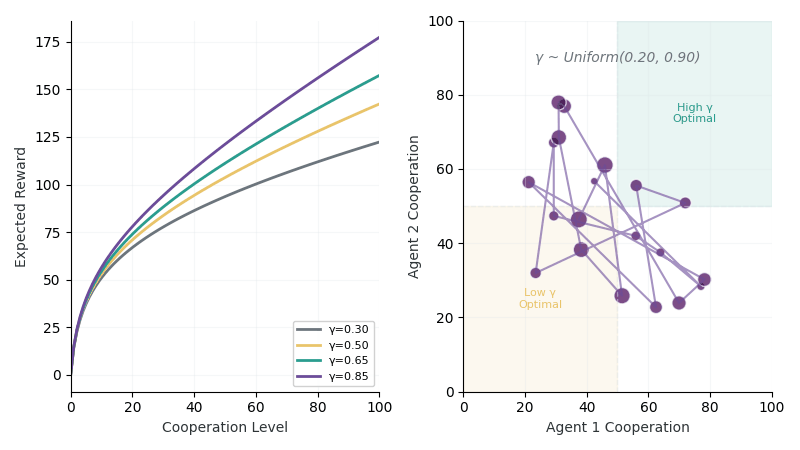 Left: Reward curves showing different returns for high (γ=0.8) vs low (γ=0.3) synergy environments. Right: Exploration trajectory as agents probe cooperation levels to infer hidden γ.
Left: Reward curves showing different returns for high (γ=0.8) vs low (γ=0.3) synergy environments. Right: Exploration trajectory as agents probe cooperation levels to infer hidden γ.
MARL Classification
| Property | Value |
|---|---|
| Game Type | Partially Observable Markov Game (hidden environment parameter) |
| Cooperation Structure | Mixed-Motive with unknown synergy multiplier |
| Observability | Partial: state visible, but γ parameter hidden (Bayes-Adaptive MDP structure) |
| Communication | Implicit (through actions only) |
| Agent Symmetry | Symmetric |
| Reward Structure | Mixed (integrated utility with hidden γ) |
| Action Space | Continuous: A_i = [0, 100] |
| State Dynamics | Deterministic (given γ), but γ unknown |
| Horizon | Finite, T = 100 |
| Canonical Comparison | Bayes-Adaptive MDP; cf. Duff (2002), Ghavamzadeh & Engel (2007) Bayesian Policy Gradient |
Formal Specification
This environment is formalized as a Bayes-Adaptive Markov Game where the complementarity parameter γ is sampled at episode start and hidden from agents.
Agents
N = {1, 2} (symmetric dyad)
| Property | Value |
|---|---|
| Endowment | 100.0 |
| Baseline | 35.0 |
| Bargaining α | 0.50 |
State Space
S ⊆ ℝ¹⁷ (standard) or ℝ¹⁸ (if γ revealed)
Standard observation excludes γ. Extended mode (reveal_gamma_in_obs=True) appends γ.
Hidden Parameter
Complementarity γ ~ Uniform(0.20, 0.90) sampled per episode
| γ Range | Classification | Optimal Strategy |
|---|---|---|
| γ > 0.60 | High Synergy | Heavy cooperation (~75%) |
| γ ≤ 0.60 | Low Synergy | Conservative (~45%) |
Action Space
A_i = [0, 100] ⊂ ℝ for each agent
Uniaxial Treatment: This environment uses the single-dimension action space characteristic of Coopetition-Gym v1.x. Competition emerges through value capture (bargaining shares) rather than explicit competitive actions.
Transition Dynamics
Standard TR-2 trust dynamics (see TrustDilemma-v0).
Trust parameters:
- λ⁺ = 0.10 (standard building)
- λ⁻ = 0.30 (standard erosion)
- τ₀ = 0.55 (moderate initial trust)
Reward Function
Rewards depend on hidden γ:
V(a₁, a₂) = θ · ln(a₁ + a₂) · (1 + γ · C(a))
where C(a) = min(a₁/e₁, a₂/e₂) is complementarity.
Key insight: Reward gradient ∂V/∂a is higher when γ is high. Agents can infer γ from reward variance.
Inference Challenge
From reward observations, agents should estimate:
P(γ | r₁, r₂, ..., rₜ) → posterior belief over γ
Optimal agent maintains belief distribution and selects actions that:
- Are optimal given current belief
- Provide information to refine belief (exploration)
Episode Structure
- Horizon: T = 100 steps
- Truncation: t ≥ T
- Termination: mean(τ) < 0.05 (trust collapse)
- Discount: γ = 1.0
Initial State
- τ_ij(0) = 0.55
- R_ij(0) = 0.00
- γ ~ Uniform(0.20, 0.90) (hidden)
Game-Theoretic Background
The Synergy Discovery Problem
Real-world parallels:
- Joint venture exploration: Firms don’t know partnership potential before trying
- Research collaboration: Complementarity of skills is discovered through work
- Merger evaluation: Synergy is uncertain until integration begins
Information Economics
The hidden γ parameter creates an information asymmetry:
- The environment knows the true γ
- Agents must infer γ from reward signals
- Optimal policy depends on the true γ value
Strategic Implications
If γ is high (>0.6):
- Heavy mutual investment is optimal
- Synergy bonus justifies high cooperation
- “High synergy” equilibrium
If γ is low (≤0.6):
- Conservative investment is optimal
- Limited synergy doesn’t justify high cooperation
- “Low synergy” equilibrium
Equilibrium Analysis
Conditional Equilibria
SynergySearch-v0 has different equilibria depending on the hidden γ:
High-Synergy Equilibrium ($\gamma > 0.60$):
| Agent | Equilibrium Action | Rationale |
|---|---|---|
| Both | $a^* \approx 75$ | High complementarity bonus justifies investment |
Total welfare: ~220 (significantly higher than baseline)
Low-Synergy Equilibrium ($\gamma \leq 0.60$):
| Agent | Equilibrium Action | Rationale |
|---|---|---|
| Both | $a^* \approx 45$ | Limited synergy reduces cooperation incentive |
Total welfare: ~165 (moderate improvement over NE)
Bayesian Nash Equilibrium
Given uncertainty about $\gamma$, agents play a Bayesian game:
Prior: $P(\gamma) = \text{Uniform}(0.20, 0.90)$ Threshold: $\gamma^* = 0.60$ (high vs. low synergy) Prior probability high synergy: $P(\gamma > 0.60) \approx 43\%$
Bayesian NE without Learning: Expected payoff-maximizing action given prior:
a_BNE = 0.43 × 75 + 0.57 × 45 ≈ 58
This “compromise” strategy is suboptimal for both γ types but hedges uncertainty.
Value of Information
The gap between informed and uninformed strategies:
| Strategy | High γ Payoff | Low γ Payoff | Expected |
|---|---|---|---|
| Optimal (informed) | 220 | 165 | 189 |
| BNE (uninformed) | 195 | 155 | 172 |
| Conservative (a=45) | 175 | 165 | 169 |
| Aggressive (a=75) | 220 | 140 | 174 |
Value of Perfect Information: VOI = 189 - 172 = 17 (≈10% improvement)
Exploration-Exploitation Tradeoff
Exploration Value: Probing actions (e.g., trying high cooperation) provide information:
- Reward from action reveals γ estimate
- Early exploration enables later exploitation
Exploration Cost:
- Suboptimal immediate payoff during probing
- Trust erosion if probing involves defection-like actions
Optimal Exploration Strategy: Given T = 100 horizon:
Exploration phase: ~3-5 steps (vary actions to estimate γ)
Exploitation phase: ~95-97 steps (play conditional equilibrium)
The short exploration phase is optimal because:
- γ can be estimated from few observations
- Long horizon makes exploitation valuable
Information Revelation Dynamics
Reward Signal Quality:
| Action Profile | Information Content |
|---|---|
| (30, 30) | Low - baseline returns similar for all γ |
| (50, 50) | Medium - some differentiation |
| (70, 70) | High - large γ-dependent bonus |
| Mixed (30, 70) | Medium - asymmetric information |
Optimal Probing:
- Use high cooperation probes (a ≈ 70-80)
- Observe reward magnitude
- Compare to expected value under γ hypotheses
Posterior Update Example
After observing reward r from action profile (70, 70):
P(γ | r) ∝ P(r | γ) × P(γ)
Expected rewards under different $\gamma$:
- $\gamma = 0.30$: $E[r] \approx 85$
- $\gamma = 0.60$: $E[r] \approx 100$
- $\gamma = 0.90$: $E[r] \approx 115$
Observing $r = 110$ strongly suggests high $\gamma$.
Theoretical Connections
Thompson Sampling Analogy: The environment structure matches Thompson Sampling problems:
- Unknown parameter (γ) with prior
- Actions provide information
- Optimal policy balances exploration/exploitation
Bayes-Adaptive MDP Structure: State space augmented with belief:
s' = (physical_state, belief_over_γ)
Optimal policy maps beliefs to actions, updating beliefs after each observation.
Multi-Agent Learning Challenges
Coordinated Exploration:
- Both agents should probe similarly for consistent signals
- Miscoordination during probing reduces information quality
- Implicit coordination through action matching
Belief Alignment:
- Agents may form different γ estimates
- Misaligned beliefs lead to coordination failure
- Communication (if available) would improve outcomes
MARL Algorithm Implications
| Algorithm | Exploration Handling | Expected Performance |
|---|---|---|
| PPO | Entropy bonus | May under-explore |
| SAC | Maximum entropy | Better exploration |
| Meta-RL (MAML) | Fast adaptation | Good for γ variation |
| Bayesian RL | Belief tracking | Optimal structure |
| RND/ICM | Curiosity bonus | Helps early exploration |
Recommended: Meta-learning or Bayesian approaches that explicitly model uncertainty.
Environment Specification
Basic Usage
import coopetition_gym
import numpy as np
# Create environment (gamma is hidden by default)
env = coopetition_gym.make("SynergySearch-v0")
obs, info = env.reset(seed=42)
# True gamma is hidden but revealed in info for analysis
print(f"True gamma: {info['true_gamma']:.3f}") # For debugging only
# Run episode
for step in range(100): actions = np.array([50.0, 50.0])
obs, rewards, terminated, truncated, info = env.step(actions)
# Check gamma type
print(f"Gamma type: {info['gamma_type']}") # "high_synergy" or "low_synergy"
Parameters
| Parameter | Default | Description |
|---|---|---|
max_steps |
100 | Maximum timesteps per episode |
gamma_range |
(0.20, 0.90) | Range for random gamma sampling |
reveal_gamma_in_obs |
False | Include gamma in observations |
render_mode |
None | Rendering mode |
Hidden Gamma Mechanism
Random Sampling
Each episode, γ is sampled uniformly:
gamma = np.random.uniform(gamma_range[0], gamma_range[1])
# gamma ∈ [0.20, 0.90]
Gamma Classification
| Range | Classification | Optimal Strategy |
|---|---|---|
| γ > 0.60 | High Synergy | Heavy investment |
| γ ≤ 0.60 | Low Synergy | Conservative investment |
Optional Revelation
For supervised learning or testing:
# Make gamma observable
env = coopetition_gym.make("SynergySearch-v0", reveal_gamma_in_obs=True)
# Gamma is now in the observation vector
obs, info = env.reset()
gamma_in_obs = obs[-1] # Last element is gamma
Observation Space
Standard Mode (gamma hidden)
| Component | Shape | Description |
|---|---|---|
| Actions | (2,) | Last cooperation levels |
| Trust Matrix | (2,2) | Pairwise trust levels |
| Reputation Matrix | (2,2) | Pairwise reputation damage |
| Interdependence | (2,2) | Structural dependencies |
| Step Info | (1,) | Normalized timestep |
Total dimension: 17
Extended Mode (gamma revealed)
Additional component: | Component | Shape | Description | |———–|——-|————-| | Gamma | (1,) | True complementarity value |
Total dimension: 18
Reward Structure
Gamma-Dependent Value
Value creation uses the hidden gamma:
V(a₁, a₂) = θ × ln(a₁ + a₂) × (1 + γ × complementarity)
Where complementarity = min(a₁/e₁, a₂/e₂).
Reward Variance
Key insight for inference:
- High gamma: Larger variance in rewards across cooperation levels
- Low gamma: Smaller variance (flatter reward landscape)
Agents can estimate gamma from:
- Absolute reward levels
- Reward changes with action changes
- Reward variance across episodes
Inference Challenge
Bayesian Perspective
Agents should ideally:
- Maintain belief distribution over γ
- Update beliefs based on rewards
- Select actions that:
- Are optimal given current beliefs
- Provide information to refine beliefs
Practical Approaches
Probing Strategy:
- Try high cooperation (e.g., 80%)
- Observe rewards
- Compare to expected rewards under different γ hypotheses
Gradient Estimation:
- Try varying cooperation levels
- Estimate ∂reward/∂action
- High gradient suggests high γ
Trust Dynamics
Parameters
| Parameter | Symbol | Value | Description |
|---|---|---|---|
| Trust Building Rate | λ⁺ | 0.10 | Standard building |
| Trust Erosion Rate | λ⁻ | 0.30 | Standard erosion |
| Initial Trust | τ₀ | 0.55 | Moderate start |
Trust dynamics are standard, not the main challenge in this environment.
Interdependence Structure
Symmetric Dependencies
D = [[ 0.00, 0.50 ],
[ 0.50, 0.00 ]]
Moderate mutual dependency creates incentive for coordination.
Metrics and Info
The info dictionary includes:
| Key | Type | Description |
|---|---|---|
step |
int | Current timestep |
true_gamma |
float | The hidden gamma value |
gamma_type |
str | “high_synergy” or “low_synergy” |
cumulative_rewards |
list | Reward history for inference |
reward_variance |
float | Variance in recent rewards |
total_value |
float | Total value created |
Optimal Strategy by Gamma
High Synergy (γ > 0.6)
# High cooperation pays off
if gamma_type == "high_synergy": optimal_coop = 0.75 # 75% of endowment
Expected dynamics:
- Rewards increase significantly with cooperation
- Trust builds easily
- Mutual high investment is stable
Low Synergy (γ ≤ 0.6)
# Conservative investment is optimal
if gamma_type == "low_synergy": optimal_coop = 0.45 # 45% of endowment
Expected dynamics:
- Rewards are relatively flat
- High investment has low ROI
- Moderate cooperation is stable
Example: Inference-Based Strategy
import coopetition_gym
import numpy as np
env = coopetition_gym.make("SynergySearch-v0")
obs, info = env.reset(seed=42)
# Probe phase: estimate gamma
probe_rewards = []
probe_actions = [30.0, 50.0, 70.0]
for probe_action in probe_actions: actions = np.array([probe_action, probe_action])
obs, rewards, _, _, info = env.step(actions)
probe_rewards.append(sum(rewards))
# Infer gamma from reward gradient
gradient = (probe_rewards[2] - probe_rewards[0]) / 40.0 # Per unit action
# High gradient suggests high synergy
estimated_high_synergy = gradient > 0.5
if estimated_high_synergy: exploit_action = 75.0
print("Inferred: HIGH synergy - using heavy investment")
else: exploit_action = 45.0
print("Inferred: LOW synergy - using conservative investment")
# Exploitation phase
for step in range(97): # Remaining steps
actions = np.array([exploit_action, exploit_action])
obs, rewards, terminated, truncated, info = env.step(actions)
print(f"True gamma: {info['true_gamma']:.3f} ({info['gamma_type']})")
print(f"Our inference was: {'CORRECT' if (info['gamma_type'] == 'high_synergy') == estimated_high_synergy else 'WRONG'}")
Research Applications
SynergySearch-v0 is suitable for studying:
- Information Economics: Learning under uncertainty
- Bayesian RL: Belief-based decision making
- Exploration-Exploitation: When and how to probe
- Meta-Learning: Adapting to new γ values
- Partner Assessment: Evaluating collaboration potential
Baseline Results
Benchmark results following the Evaluation Protocol.
Evaluation Configuration
| Parameter | Value |
|---|---|
| Episodes | 100 |
| Seeds | 0-99 |
| Horizon | 100 steps |
| γ distribution | Uniform(0.20, 0.90) |
Performance Comparison
| Algorithm | Mean Return | High γ Return | Low γ Return | Inference Acc |
|---|---|---|---|---|
| Random | 156.2 | 165.4 | 148.6 | 50% |
| Constant(0.50) | 172.4 | 175.2 | 169.8 | - |
| Constant(0.75) | 186.8 | 212.4 | 165.2 | - |
| BNE(0.58) | 178.6 | 188.2 | 170.4 | - |
| Probe+Exploit | 194.2 | 218.6 | 173.2 | 82% |
| IPPO | 182.4 | 198.6 | 168.5 | 68% |
| Meta-RL (MAML) | 198.4 | 222.3 | 178.2 | 86% |
Inference Acc = % of episodes where agent correctly identified high/low synergy.
Exploration Strategy Analysis
| Strategy | Exploration Steps | Regret (vs Optimal) |
|---|---|---|
| No exploration | 0 | 18.2 |
| Fixed 3-step probe | 3 | 8.4 |
| Adaptive probe | 2-5 | 5.6 |
| Thompson Sampling | Continuous | 4.2 |
| Meta-RL | Learned | 3.8 |
Key Observations
- Inference matters: Correct γ identification improves returns by ~15%
- Exploration cost: ~3 probing steps is optimal given T=100 horizon
- Meta-learning advantage: MAML-style approaches learn efficient exploration
- Conservative bias: Under-exploration leads to suboptimal conservative play
Recommended Hyperparameters
# Meta-RL configuration for SynergySearch-v0
algorithm: MAML-PPO
inner_lr: 0.1
outer_lr: 3e-4
adaptation_steps: 3
meta_batch_size: 20
network: hidden_layers: [128, 128]
Related Environments
- TrustDilemma-v0: Known parameters
- RecoveryRace-v0: Another benchmark challenge
- SLCD-v0: Fixed validated parameters
References
- Ghavamzadeh, M. & Engel, Y. (2007). Bayesian Policy Gradient Algorithms. NeurIPS.
- Duff, M.O. (2002). Optimal Learning: Computational Procedures for Bayes-Adaptive MDPs. UMass Dissertation.
- Pant, V. & Yu, E. (2025). Computational Foundations for Strategic Coopetition: Formalizing Interdependence and Complementarity. arXiv:2510.18802